Markov Chains
This week in Programming A to Z we learned about Markov Chains as a method for generating new text based on a source text. Named after Adrey Markov, Markov Chains are a mathematical system to navigate between different “states” based on a probability table. On a granular level these tables show the number of times that something such as a word or a segment of text of a predetermined length is followed by another word or segment of text. This table can then be used to generate new text probabilistically in a way that matches patterns in the original input.
For my own experimentation with Markov Chains I chose to work with the text of Me Talk Pretty One Day by David Sedaris. This is one of my favorite novels and since I would be experimenting with varying the attributes of the analysis of the source text I was especially curious to see if it was possible to mirror Sedaris’ dry wit.
As a quick detour I think it is necessary to address an elephant in the room: copyright law. I am intentionally not posting the text file of my source text online, however I am of the opinion that my use of the text of this book, being something that I purchased legally, fits squarely into the category of “fair use”. It would be perfectly legal for me to tear my paper copy into shreds and rearrange all of the words into a physical form of a Markov Chain generation. By extension of that logic I think it is also fair for me to do this in a digital form. While I am not an expert on matters of copyright law I highly recommend Free Culture by Lawrence Lessig (available for free under a creative commons license) as a deeper dive into the topic and its history.

My experimentation broke down into two portions, first analyzing the source text based on character segments of varying length, then a second analysis based on words.
From initial observations text generated using short character segments of 2 to 4 characters created lots of incoherent gibberish.
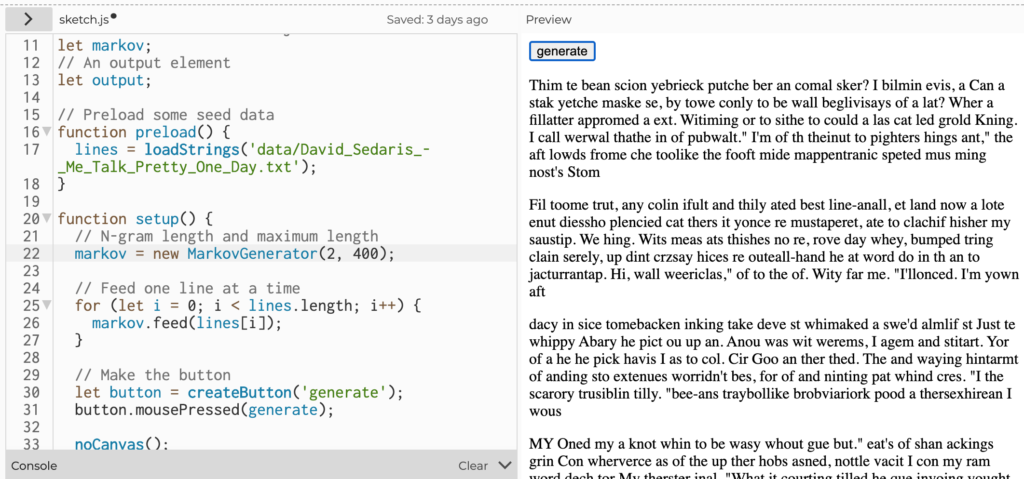
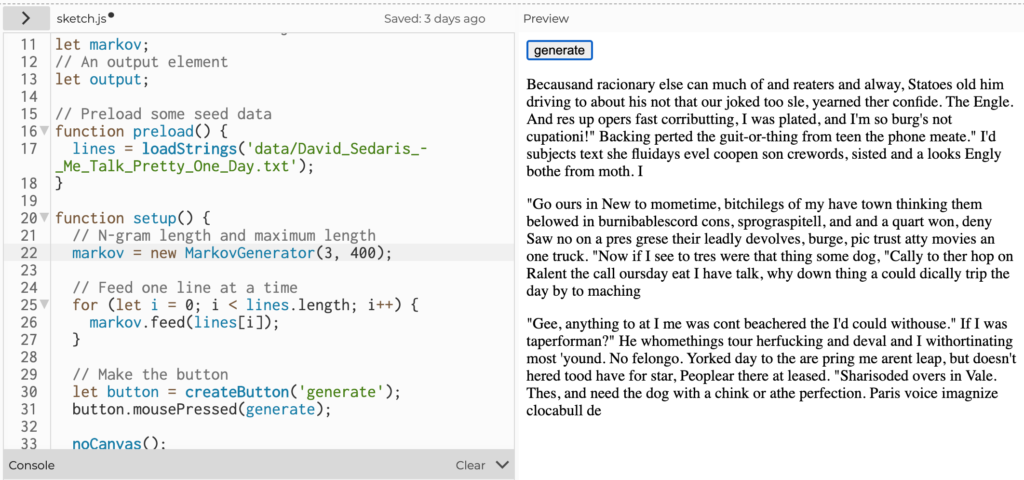
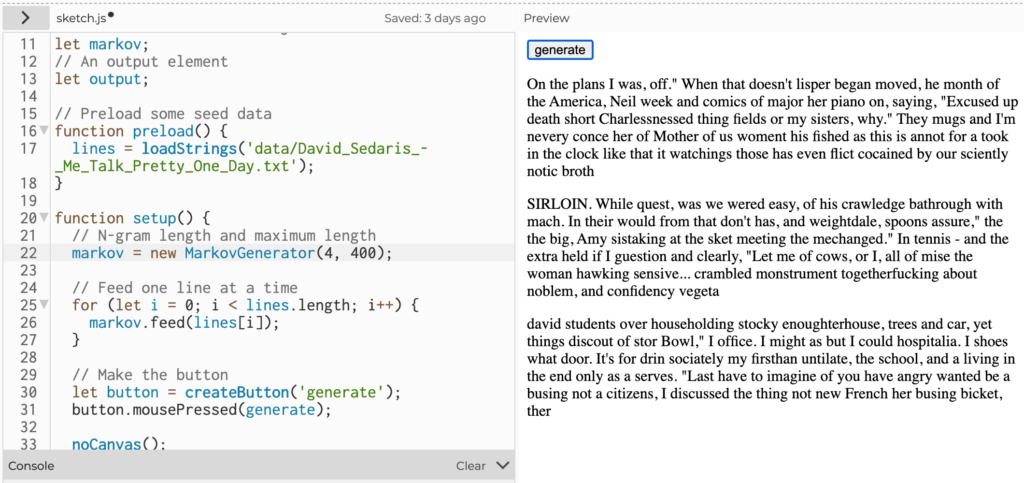
Expanding the Markov Chains to make use of character counts from 5 to 7 characters resulted in longer segments that became real words but still largely nonsensical combinations.
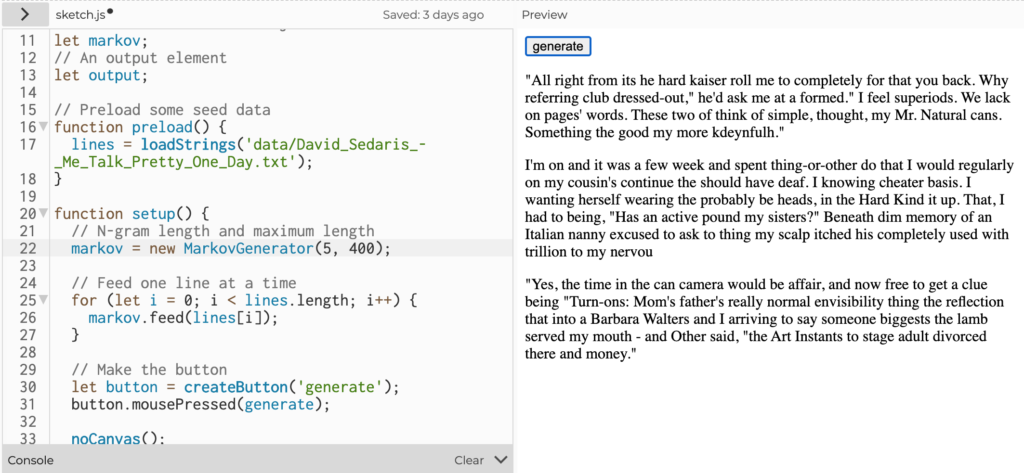
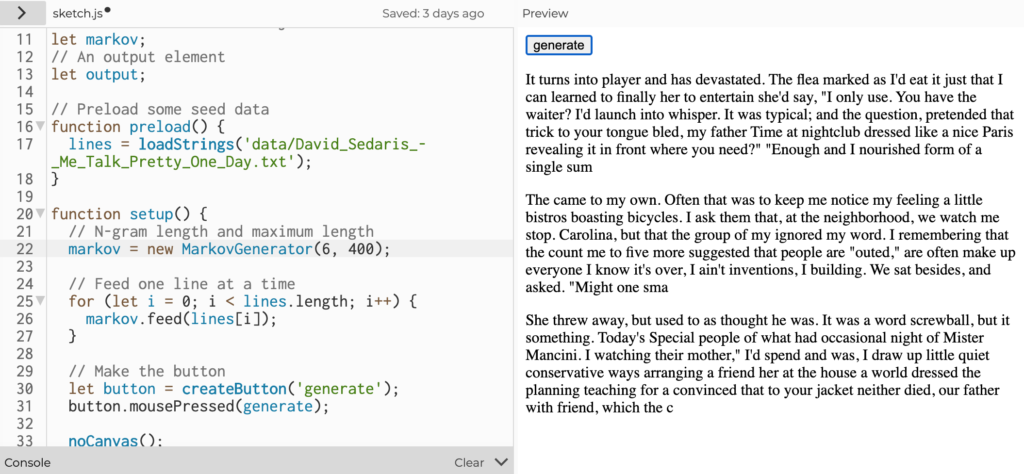
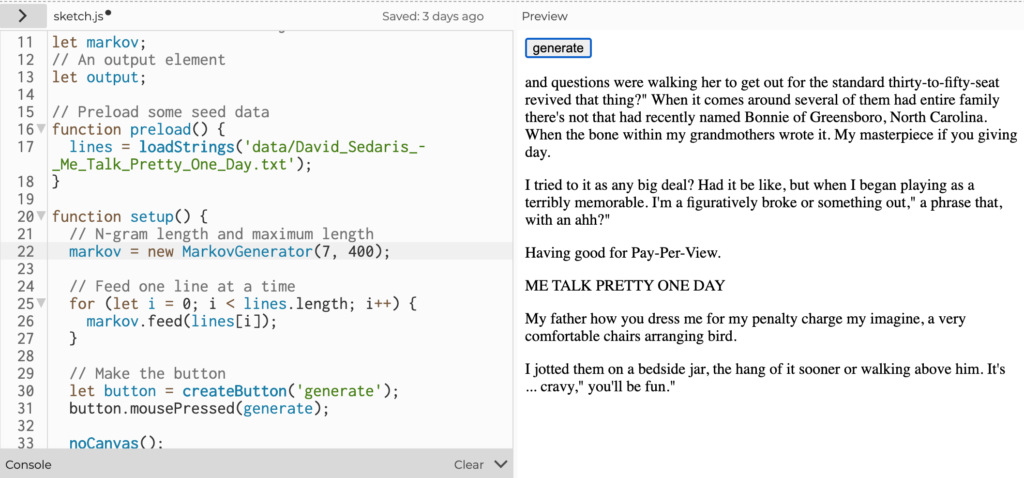
The humor of turning Sedaris’ work from a tragic comedy about learning foreign languages into gibberish with Markov Chains was not lost on me. One of my favorite generated sentences along this theme included: “It was a word screwball, but it something.”
Yes, it certainly was SOMETHING!
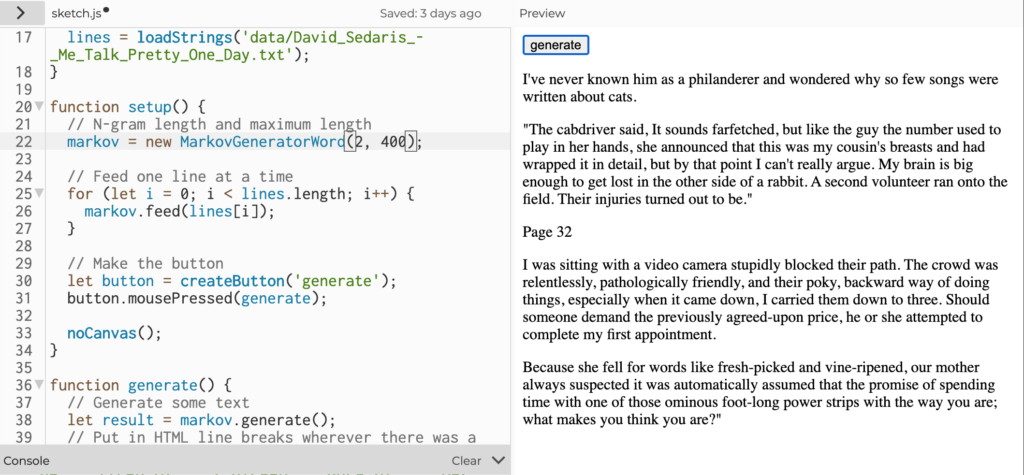
My next test made use of short word chains. Here using two word chains were still about as nonsensical as the character chains including this beauty of a sentence “I’ve never known him as a philanderer and wondered why so few songs were written about cats.”
Moving to long word chains had an unintended consequence of generating text that was eerily similar to the original input… and after a quick search occasionally revealed as full quotes from source text.
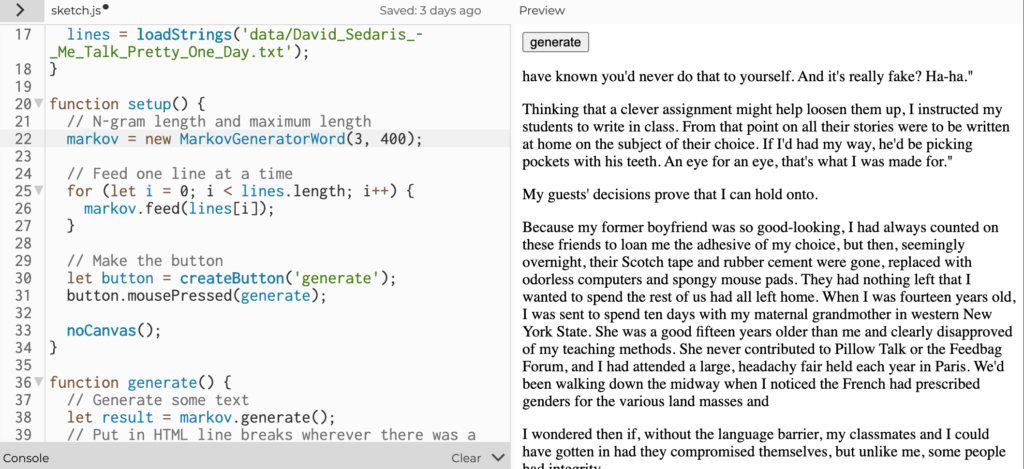
My final observation is that generating coherent and original text with Markov Chains is difficult! It may also be necessary to build in a function to determine whether the generated text is truly “remixed” and not just a full quote from the original input.


