Word Counting
This week for Programming A to Z I made an attempt at creating a word counting algorithm. Coming off of the first round of (Presidential)? debates I was feeling inspired to do some word counting to determine what words were most commonly said by each of the speakers.
The transcript I was able to locate online had a standard formatting that looked perfect to tackle with one of the tools we have been learning to use in Programming A to Z: Regular Expressions!

Looking over the transcript there appeared to be a somewhat regular formatting of timecode and names in capital letters, indicate who was speaking, followed by a line break, and what they said. Starting here I lead me to this regular expression:
((\d:)?(\d)?\d:\d\d )?((PRESIDENT DONALD )?TRUMP*|(JOE )?BIDEN*|(CHRIS )?WALLACE*)\n
What a mess! But it worked to select the timecode and names including some of the variations in the transcript.
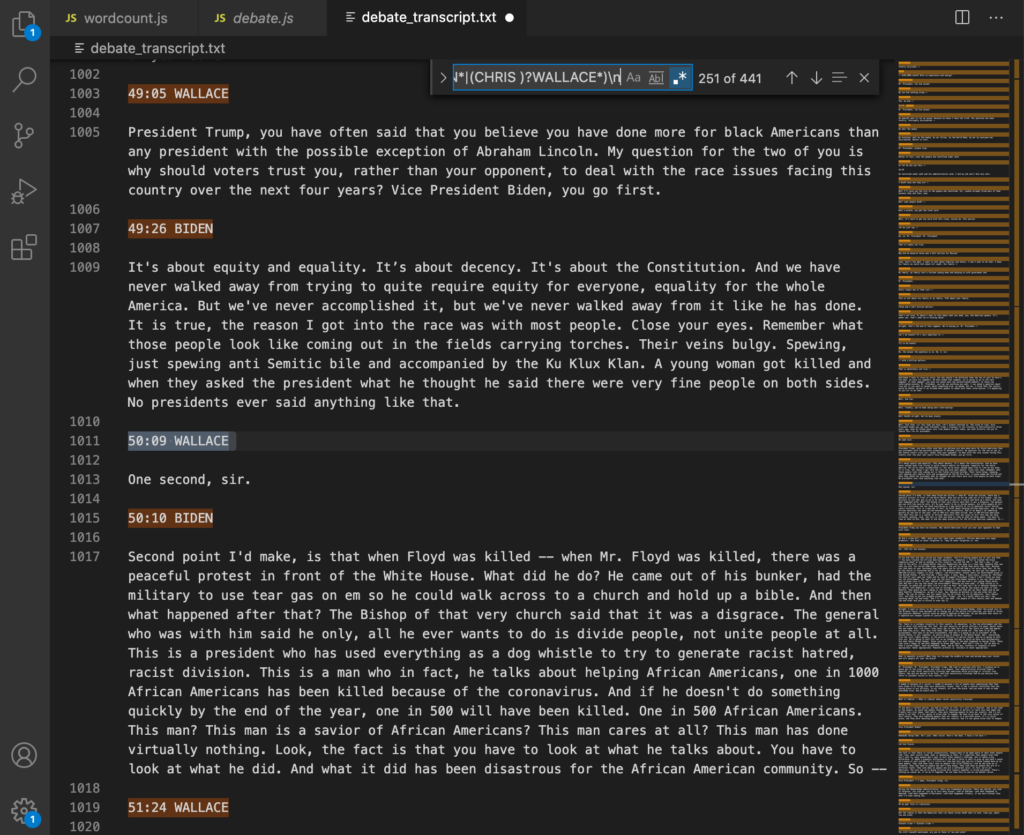
Next I added a lookbehind to the regular expression to invert the selection:
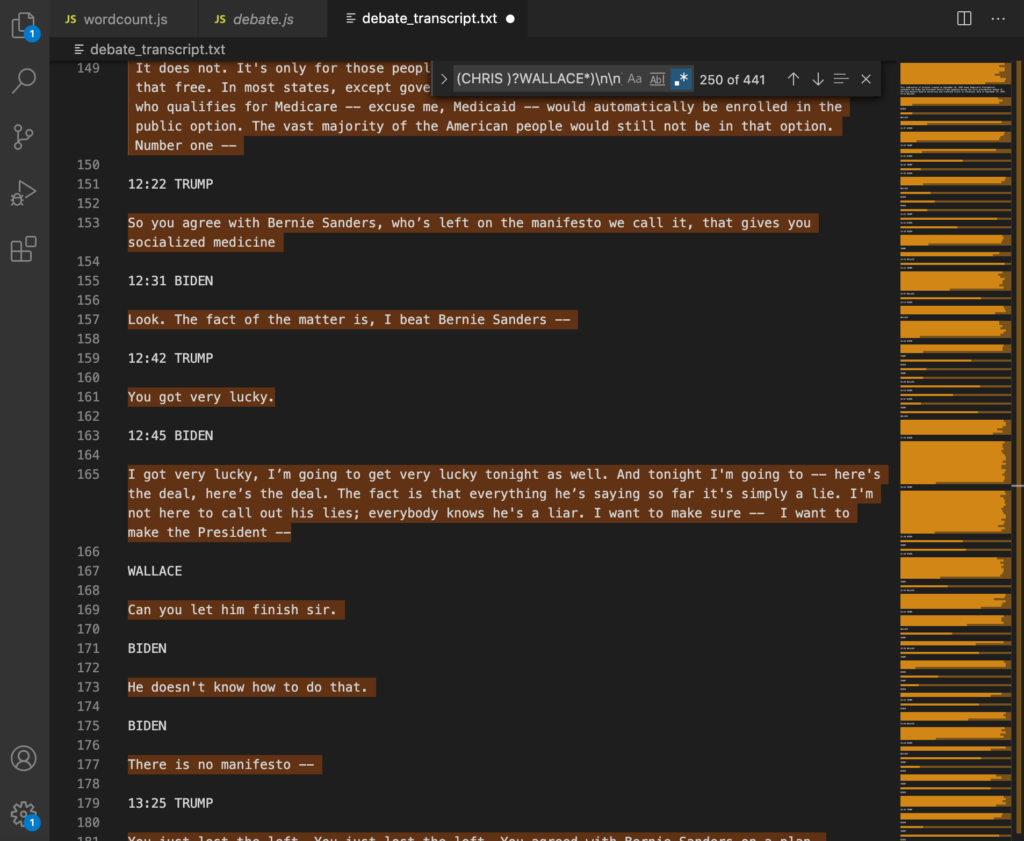
Then took out the OR operator to create three distinct regular expressions: one for the moderator and another for each of the candidates.
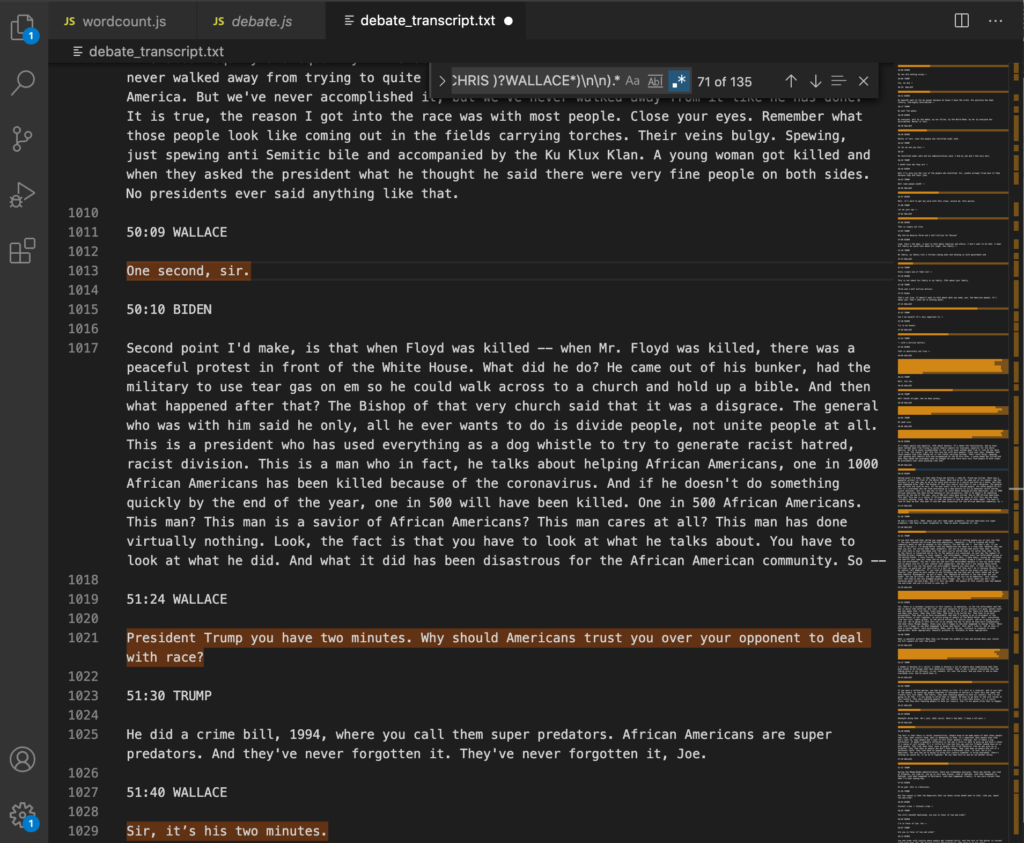
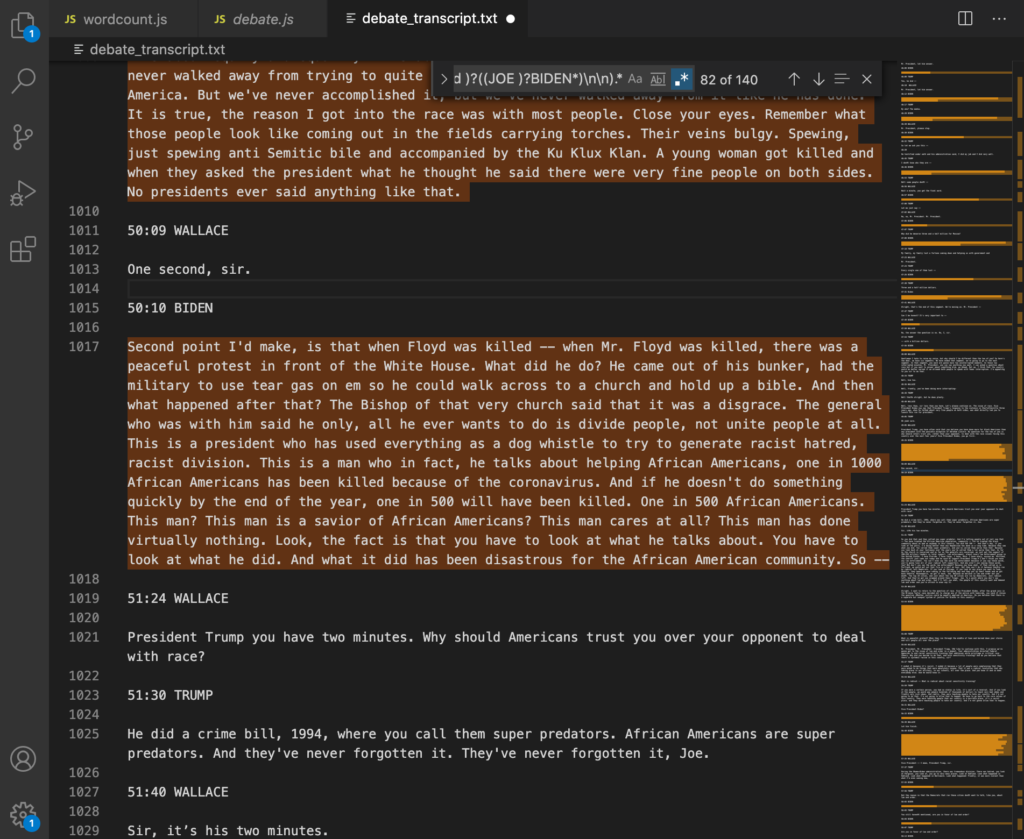
At this point I was left with the following three regular expressions:
//Tump only (?<=((\d:)?(\d)?\d:\d\d )?((PRESIDENT DONALD )?TRUMP*)\n\n).* //Biden only (?<=((\d:)?(\d)?\d:\d\d )?((JOE )?BIDEN*)\n\n).* //Wallace only (?<=((\d:)?(\d)?\d:\d\d )?((CHRIS )?WALLACE*)\n\n).*
This was working well but took much more effort than I anticipated!
My thought at this point was to take the regular expressions into Javascript and run the text of each through a word counting algorithm. After some stumbles with the code and lots of time spent troubleshooting I realized that the lookbehind I was attempting to use was not playing well with the match() function in Javascript. After some further digging I learned that lookbehinds have not historically been supported by Javascript at all! Oh boy. While I had been testing in Safari and hitting my head against a wall I found that Chrome did have experimental support for lookbehinds.
At this point I found myself with some functioning code and was able to roughly count the words by speaker using the code below. With more time I would like to create a visualization for this data!
var txt;
var trumpCounts = {};
var bidenCounts = {};
var wallaceCounts = {};
var trumpKeys = [];
var bidenKeys = [];
var wallaceKeys = [];
async function fetchURL(url) {
try {
const response = await fetch(url);
txt = await response.text();
// Trump only
let trump = txt.match(/(?<=((\d:)?(\d)?\d:\d\d )?((PRESIDENT DONALD )?TRUMP*)\n\n).*/g);
trump = trump.toString();
let trumpTokens = trump.split(/\W+/);
//console.log(trumpTokens);
for (var i = 0; i < trumpTokens.length; i++) {
var word = trumpTokens[i].toLowerCase();
if (trumpCounts[word]){
trumpCounts[word]++;
} else {
trumpCounts[word] = 1;
trumpKeys.push(word);
}
}
// Biden only
let biden = txt.match(/(?<=((\d:)?(\d)?\d:\d\d )?((JOE )?BIDEN*)\n\n).*/g);
biden = biden.toString();
let bidenTokens = biden.split(/\W+/);
//console.log(bidenTokens);
for (var i = 0; i < bidenTokens.length; i++) {
var word = bidenTokens[i].toLowerCase();
if (bidenCounts[word]){
bidenCounts[word]++;
} else {
bidenCounts[word] = 1;
bidenKeys.push(word);
}
}
// Wallace only
let wallace = txt.match(/(?<=((\d:)?(\d)?\d:\d\d )?((CHRIS )?WALLACE*)\n\n).*/g);
wallace = wallace.toString();
let wallaceTokens = wallace.split(/\W+/);
//console.log(wallaceTokens);
for (var i = 0; i < wallaceTokens.length; i++) {
var word = wallaceTokens[i].toLowerCase();
if (wallaceCounts[word]){
wallaceCounts[word]++;
} else {
wallaceCounts[word] = 1;
wallaceKeys.push(word);
}
}
//console.log(trumpCounts);
//console.log(bidenCounts);
//console.log(wallaceCounts);
} catch (err) {
console.error(err);
}
}
fetchURL('/itp/fall2020/debate/debate_transcript.txt');


